

فایل Robots.txt چیست؟
وظیفه فایل robots.txt محدود کردن دسترسی روبات های گوگل و سایر موتورهای جستجو به محتویات سایت شماست. این روبات ها بصورت کاملا اتوماتیک عمل کرده و قبل از ورود به هر سایت یا صفحه ای از وجود فایل robots.txt بر روی آن و محدود نبودن دسترسی محتوا مطمئن می شوند. تمامی روبات های استاندارد در اینترنت به این قوانین و محدودیت ها احترام گذاشته و صفحات شما را بازدید و ایندکس نخواهند کرد ولی روبات های اسپم توجهی به این فایل نخواهند داشت. اگر تمایل به حفظ امنیت محتوایی خاص و پنهان کردن آن از دید روبات های اینترنتی دارید بهتر است از پسورد گذاری صفحات استفاده کنید.
در عمل استفاده از فایل robots.txt به شما این امکان را میدهد که صفحات سایت را تنها مختص کاربران اینترنتی طراحی کرده و ترسی از محتوای تکراری، وجود لینک های بسیار در آن صفحه و تاثیر منفی بر سئو سایت نداشته باشید. همچنین به شما این امکان را میدهد که صفحات بی ارزش و کم محتوا را از دید موتورهای جستجو پنهان کنید تا زمان روبات ها در سایت شما برای ایندکس کردن این صفحات هدر نرود.
شما تنها زمانیکه قصد محدود کردن روبات های گوگل را داشته باشید از فایل robots.txt استفاده میکنید و اگر از نظر شما تمام صفحات سایت قابلیت و ارزش ایندکس شدن توسط گوگل را داشته باشند نیازی به این فایل نخواهید داشت. حتی قرار دادن یک فایل خالی با همین نام نیز لزومی ندارد.
برای قرار دادن یک فایل robots.txt شما باید به هاست دسترسی داشته و آن را در ریشه اصلی کپی کنید. اگر به هر دلیل دسترسی شما به سرور محدود شده باشد میتوانید با قرار دادن تگ های متا در هدر صفحه دسترسی روبات به آن را محدود کنید.
برای جلوگیری از ورود تمامی روبات های اینترنتی به صفحه از تگ:
<meta name=”robots” content=”noindex” />
و برای محدود کردن روبات های گوگل از تگ:
<meta name=”googlebot” content=”noindex” />
استفاده کنید. با مشاهده ی این تگ در هدر یک صفحه گوگل بطور کلی آن را از نتایج جستجوی خود خارج خواهد کرد.
آموزش ساخت فایل robots.txt
یک فایل ساده برای مدیریت روبات های اینترنتی از دو قانون اصلی استفاده میکند که عبارتند از:
User-agent: نشان دهنده نوع روباتی است که نباید به صفحه دسترسی داشته باشد.
Disallow: بیانگر آدرس صفحه ای است که میخواهید از دید روبات ها پنهان بماند.
با ترکیب این دو دستور شما میتوانید قوانین مختلفی را برای دسترسی به صفحات داخلی سایت تعریف کنید. بعنوان مثال برای یک user-agent مشخص میتوان چندین آدرس را معرفی نمود و یا برعکس.
لیست تمامی روبات های اینترنتی معتبر در دیتابیس Web Robots Database موجود است و شما میتوانید با قرار دادن نام هریک بعنوان User-agent قوانین مشخصی برای آنها تعریف کنید و یا با استفاده از کاراکتر * به جای نام در فایل robots.txt یک قانون را برای همه روبات ها اعمال کنید. مانند:
User-agent: *
Disallow: /folder1/
موتور جستجوی گوگل چندیدن نوع روبات مخصوص بخود دارد که معروفترین آنها با نام Googlebot شناخته میشود و وظیفه بررسی و ایندکس صفحات وب را برعهده دارد. روبات Gogglebot-image نیز مسئول بررسی تصاویر سایت ها و ایندکس کردن آنها می باشد.
User-Agent: Googlebot
Disallow: /folder2/
شما میتوانید به روش های مختلفی قوانین خود را اعمال کنید، میتوان یک صفحه مشخص و یا یک دسته از صفحات را برای یک قانون تعریف نمود. مثال های زیر روش های مختلف استفاده از این قوانین هستند:
برای عدم دسترسی روبات ها به تمام محتویات سایت از کاراکتر / استفاده میکنیم
Disallow: /
برای عدم دسترسی به یک فولدر یا دسته از سایت نام آن را وارد کنید
Disallow: /blog/
برای اعمال محدودیت روی یک صفحه خاص آدرس دقیق آن را بدون نام سایت وارد کنید
Disallow: /blog/keyword-planner/
برای محدود کردن یک تصویر بر روی سایت آدرس آن را بهمراه User-agent مربوط به آن وارد کنید
User-agent: Googlebot-Image
Disallow: /images/dogs.jpg
و برای مخفی کردن تمام تصاویر موجود بر روی سایت از دید موتورهای جستجو از دستور زیر استفاده کنید
User-agent: Googlebot-Image
Disallow: /
همچنین شما میتوانید یک نوع فایل مشخص را از دید موتورهای جستجو مخفی نگه دارید، بعنوان مثال برای تصاویری با فرمت gif
User-agent: Googlebot
Disallow: /*.gif$
توجه داشته باشید که فایل robots.txt نسبت به بزرگ و کوچک بودن حروف انگلیسی حساس بوده و آدرس صفحات باید به دقت وارد شوند. پس از ساخت فایل مورد نظر خود و ذخیره آن در فرمت txt آن را بر روی سرور و در ریشه اصلی کپی کنید. قوانین اعمال شده برای روبات هایی هستند که از این پس به سایت شما وارد میشوند حذف صفحاتی که در گذشته ایندکس شده اند از دیتابیس گوگل نیازمند گذشت زمان خواهد بود.
آزمایش Robots.txt در بخش Blocked URLs وبمستر
وبمستر گوگل قسمت مشخصی را برای نمایش صفحاتی از سایت شما که توسط robots.txt دسترسی روبات به آنها محدود شده، در نظر گرفته است. این صفحه با نام Blocked URLs و بعنوان زیر مجموعه ای از بخش Crawl تعریف شده است.
برای اطمینان از عملکرد صحیح فایل robots.txt به بخش Blocked URLs در اکانت وبمستر خود مراجعه کرده و مانند تصویر زیر در بخش اول محتویات فایل را کپی کنید. در بخش دوم آدرس صفحاتی که قصد دارید میزان محدودیت روبات های گوگل در دسترسی به آنها را بسنجید وارد کنید. (در هر خط یک آدرس)
در بخش انتهایی شما میتوانید یک نوع از روبات های گوگل را علاوه بر روبات اصلی که وظیفه ایندکس صفحات را برعهده دارد انتخاب کنید.
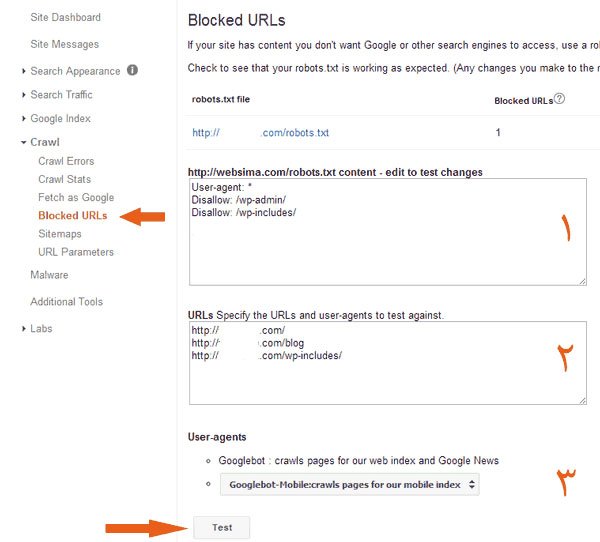
نمایی از صفحه Blocked urls در وبمستر گوگل
با فشردن دکمه Test نتایج آزمون و میزان دسترسی روبات ها به هریک از این آدرس ها به شما نمایش داده خواهد شد.

نمونه ای از نتایج آزمایش فایل Robots.txt
نحوه انتخاب صفحاتی که در فایل robots.txt معرفی می شوند و پنهان کردن آنها از دید موتورهای جستجو وابستگی مستقیم با سیاست های شما در انتشار محتوا و سئو سایت خواهد داشت. قبل از انجام تغییرات اساسی در این فایل حتما با متخصصان سئو مشورت کرده و کدهای وارد شده را چندین بار آزمون و بازنویسی نمایید. در صورتیکه در مورد هریک از موارد عنوان شده در این مقاله سوال یا ابهامی دارید میتوانید در بخش نظرات مطرح کرده و تا حد توان کارشناسان وبسیما پاسخ گوی شما خواهند بود.




دیدگاهها (0)